Comparison
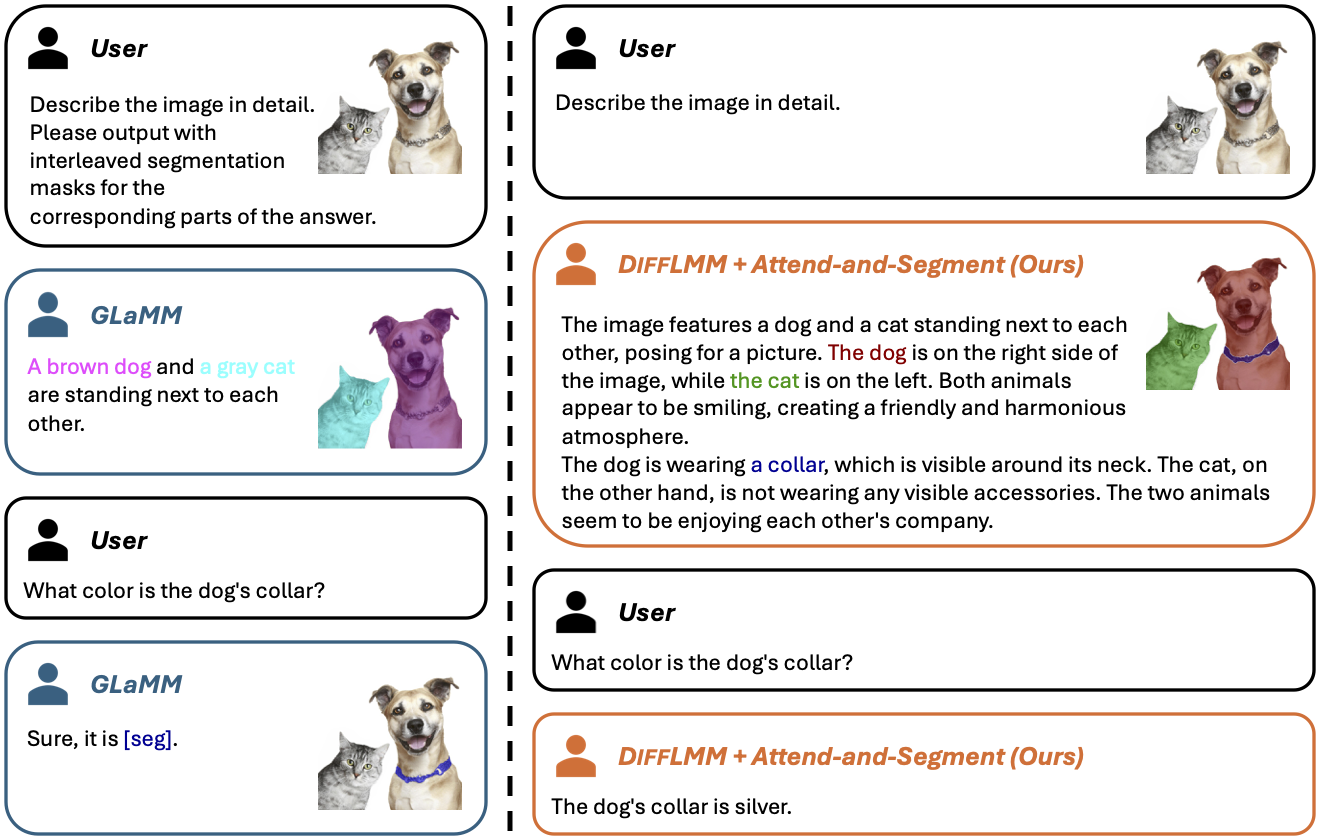
Grounded conversations with GLaMM vs. our approach, DiffLMM + Attend-and-Segment. As a state-of-the-art grounding LMM, GLaMM is trained to relate text phrases with segmentation masks while generating a response. However, due to limitations induced by the grounding supervision, it often fails to precisely follow the human user's instructions (e.g., describing the image in detail, answering the correct color). Our approach reveals and enhances the grounding ability implicitly learned by LMMs without explicit grounding supervision, which leads to visually grounded responses while preserving the general vision-language conversation ability of LMMs.
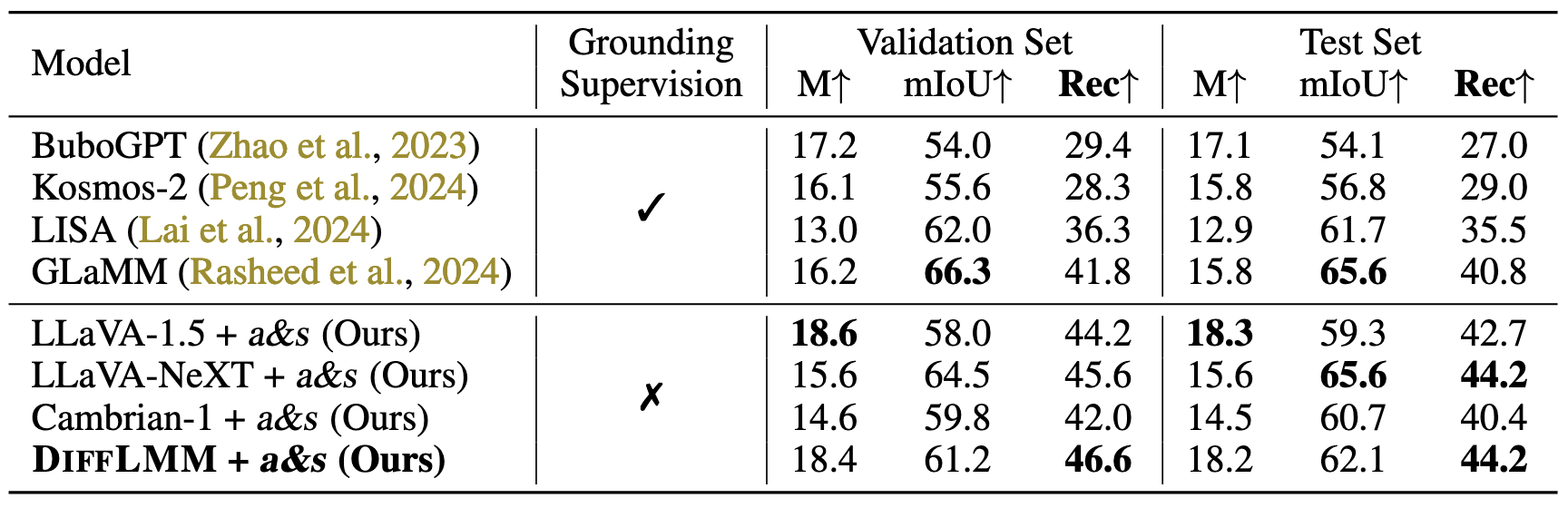
Grounded conversation generation (GCG) results. Even without grounding supervision, Attend-and-Segment (a&s in the table) unlocks the implicitly learned grounding ability in LLaVA-1.5, outperforming all grounding-specific models on this task. DiffLMM further enhances the grounding ability, and leads to stronger grounding performance. The higher METEOR scores demonstrate our better preserved conversation ability. As a general approach, Attend-and-Segment can be applied on different LMMs (e.g., LLaVA-NeXT and Cambrian-1).
Approach
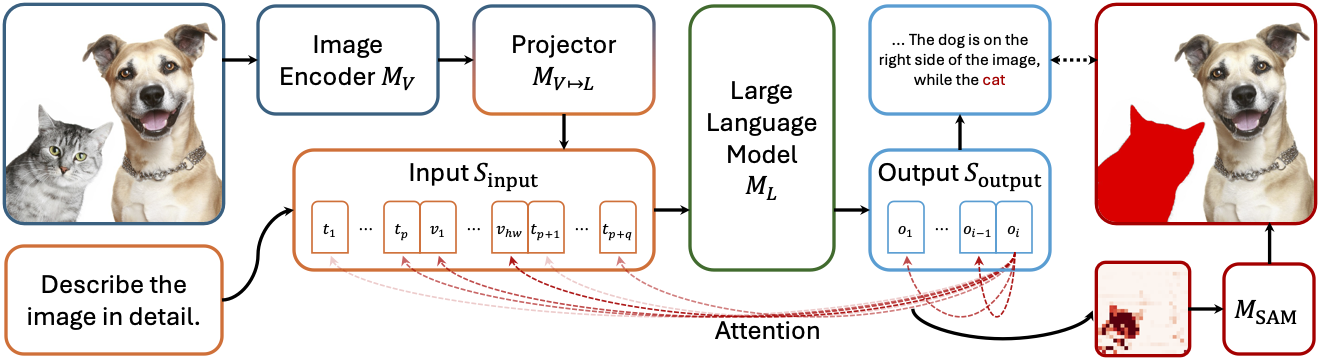
Meta-architecture of LMMs and the Attend-and-Segment strategy. When generating a new token (e.g., "cat") which requires grounding, we capture the attention between the new token and the input visual tokens. Then SAM is employed to refine the processed attention map into a segmentation mask (e.g., cat in the image).
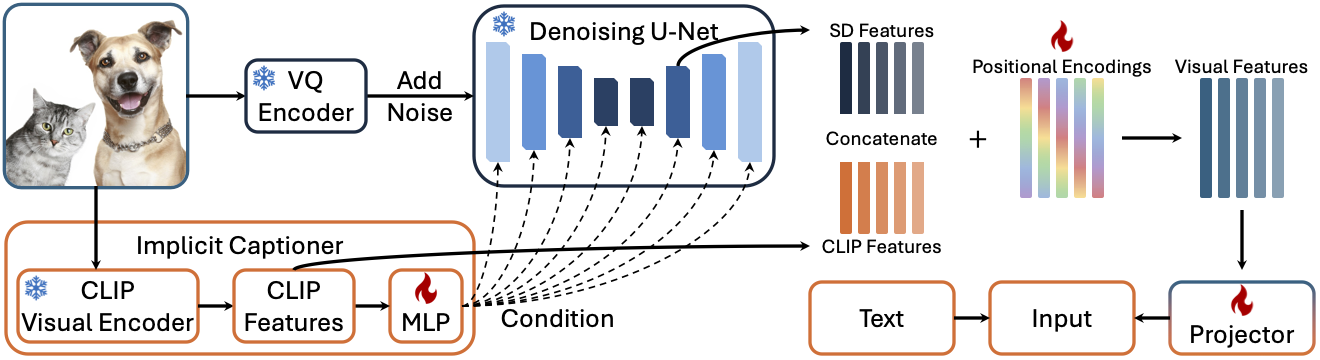
Visual encoding in DiffLMM. We perform one denoising step with the diffusion model (DM), and extract visual features from an intermediate block of the U-Net. The implicit captioner produces text-like conditioning and improves the visual features in the U-Net. We combine both DM features and CLIP features, and add learnable positional encodings to them. The final visual features are projected into the language feature space, and fed into the LLM along with other text tokens. The DM and CLIP visual encoder are frozen.
More Interesting Examples
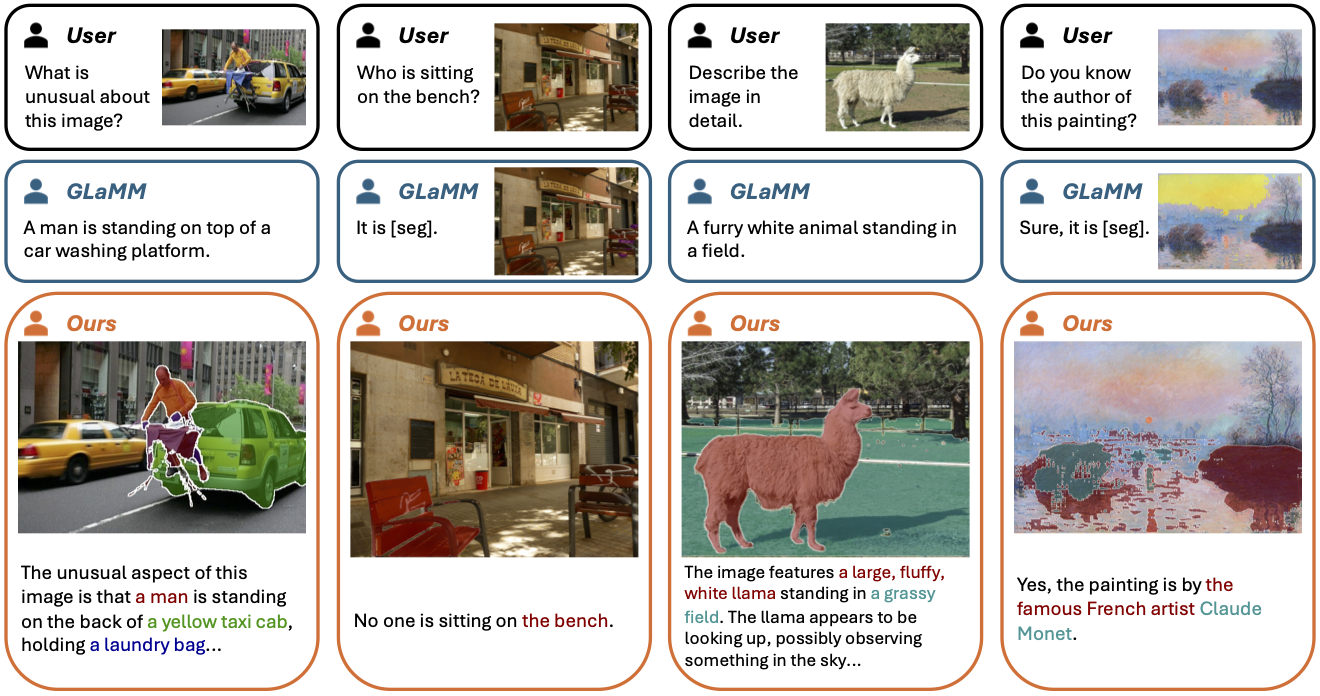
Comparison of model responses to challenging visual questions. 1) Unusual image contents: The model is requested to analyze the unusual aspect of a given image. 2) Adversarial questions: The model is asked about something that does not exist in the image. 3) Rare visual concepts: The image contains objects of less frequent categories. 4) Shifted image domain: An image from a new domain is given to the model.